使用HashSet/TreeSet时,必须为类定义equals();而HashCode()是针对HashSet,作为一种编程风格,当覆盖equals()的时候,就应该同时覆盖hashCode().
一:String,StringBuffer,StringBuilder 的区别
三者在执行速度方面的比较:StringBuilder > StringBuffer > String
String与StringBuffer的区别简单地说,就是一个变量和常量的关系。StringBuffer对象的内容可以修改;而String对象一旦产生后就不可以被修改,重新赋值其实是两个对象。 StringBuffer 的内部实现方式和String不同,StringBuffer在进行字符串处理时,不生成新的对象,在内存使用上要优于String类。所以在实际使用 时,如果经常需要对一个字符串进行修改,例如插入、删除等操作,使用StringBuffer要更加适合一些。
StringBuilder:线程非安全的 StringBuffer:线程安全的
当我们在字符串缓冲去被多个线程使用是,JVM不能保证StringBuilder的操作是安全的,虽然他的速度最快,但是可以保证 StringBuffer是可以正确操作的。当然大多数情况下就是我们是在单线程下进行的操作,所以大多数情况下是建议用StringBuilder而不 用StringBuffer的,就是速度的原因。
2.字符和数字
在我多年的开发经验中,经常发现的一个情况就是,很多项目的对象字段或者是数据库字段本来是数字类型的,却被定义成字符串类型,这无关痛痒吗?
对于小项目来说,可能没什么影响,反正只要业务逻辑正确即可,性能没什么问题,因为数据也不多,用户也不多。
然而,对于大数据处理来说,这个可不是小事,从字符串替换为数字类型,可以极大地节省内存、磁盘存储以及网络带宽,减少IO的代价,而且很多数据结构和算法使用数字类型比字符串要更快。
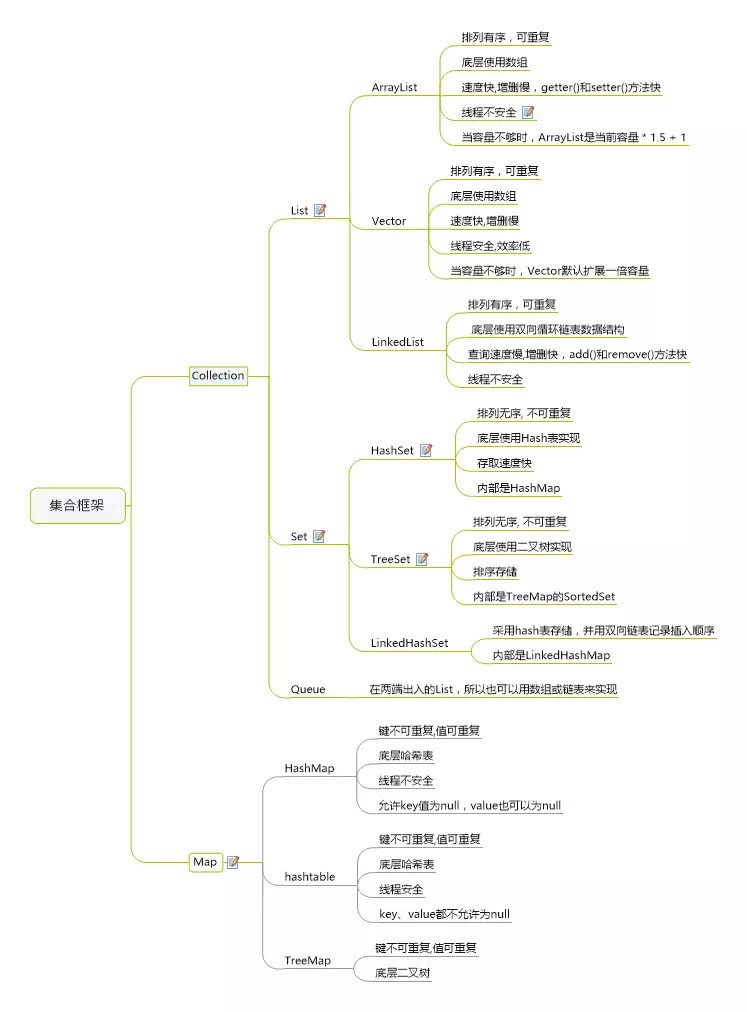
二:java集合
集合类和接口如下:
Collection接口下--
├List (inteface) 有序,允许重复
│├LinkedList 在实现中采用链表数据结构。插入和删除速度快,访问速度慢。
│├ArrayList 代表长度可以改变得数组。可以对元素进行快速随机的访问。
│└Vector 非常类似ArrayList 但Vector是同步,线程安全的,多线程开发中使用。如果不考虑到线程的安全因 素,一般用arraylist效率比较高
│ └Stack
└Set(inteface) 无序,不允许重复
| |-HashSet 是哈希表实现的,无序的结合,为快速查找而设计的Set ,存入HashSet对象必须定义hashCode().
| |-TreeSet是红黑树实现的,排序的集合 ,使用它可以从Set 中提取有序序列.
| |--LinkedHashSet 具有HashSet的查询速度,且内部使用链表维护元素的次序.
使用HashSet/TreeSet时,必须为类定义equals();而HashCode()是针对HashSet,作为一种编程风格,当覆盖equals()的时候,就应该同时覆盖hashCode().
Map接口--
├Hashtable
├HashMap 基于散列表的实现,在Map 中插入、删除和定位元素,HashMap 是最好的选择
└WeakHashMap
|-TreeMap 基于红黑树数据结构的实现,有序的
hashtable与hashmap的区别
一.历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现
二.同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的
三.值:只有HashMap可以让你将空值作为一个表的条目的key或value
三:java中hashcode的作用
以下是关于HashCode的官方文档定义:
- hashcode方法返回该对象的哈希码值。支持该方法是为哈希表提供一些优点,例如,java.util.Hashtable 提供的哈希表。
- hashCode 的常规协定是:
- 在 Java 应用程序执行期间,在同一对象上多次调用 hashCode 方法时,必须一致地返回相同的整数,前提是对象上 equals 比较中所用的信息没有被修改。从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。
- 如果根据 equals(Object) 方法,两个对象是相等的,那么在两个对象中的每个对象上调用 hashCode 方法都必须生成相同的整数结果。
- 以下情况不 是必需的:如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么在两个对象中的任一对象上调用 hashCode 方法必定会生成不同的整数结果。但是,程序员应该知道,为不相等的对象生成不同整数结果可以提高哈希表的性能。
- 实际上,由 Object 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,但是 JavaTM 编程语言不需要这种实现技巧。)
- 当equals方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。
以上这段官方文档的定义,我们可以抽出成以下几个关键点:
1、hashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址的;
2、如果两个对象相同,就是适用于equals(java.lang.Object) 方法,那么这两个对象的hashCode一定要相同;
3、如果对象的equals方法被重写,那么对象的hashCode也尽量重写,并且产生hashCode使用的对象,一定要和equals方法中使用的一致,否则就会违反上面提到的第2点;
4、两个对象的hashCode相同,并不一定表示两个对象就相同,也就是不一定适用于equals(java.lang.Object) 方法,只能够说明这两个对象在散列存储结构中,如Hashtable,他们 “存放在同一个篮子里”。